Hello, Jeremy mentioned I might share a few words here about the AIMagic experience that Nate and I had during the CUDA IRL hackathon last weekend. So here’s a quick post on it.
As I mentioned previously in a mini-update, at the CUDA IRL hackathon, Nate and I tried to push AIMagic for code generation as far as we could, by using it to build a pure-C implementation of stable diffusion with training and inference.
This was inspired by a talk that Karpathy gave at the event, about how he developed llm.c by translating the PyTorch GPT2 implementation into C, function by function, with assistance from ChatGPT, and also by the idea of “CUDA mode,” Tim Dettmers’s special brain state of intense, CUDA-only focus. So we figured we’d use the hackathon to try to do exactly the same thing but with a stable diffusion model, and put the LLM itself into “CUDA mode”.
This worked way better than we expected. Our project was one of the 10 picked in competition, so I ended up presenting it at the end of day (around 10pm lol). But I could only talk about all the C code, rather than reveal our AIMagic secret sauce.1 😦
But fortunately everyone here can see not only the expurgated public repo, but also the private repo with the notebook as well as the generated ~1,300 lines of C code. The notebook shows our approach.
AIMagic CUDA mode
Here’s some short notes on our approach:
-
We loaded in a lot of context without much editing: 3 transcripts of Jeremy’s tutorial videos, the entire llm.c code base, and the entire python diffusors codebase.
-
We relied on Sonnet-3.5 to generate the plan for the work, and then just asked it to do the work one step at a time. Sometimes it would do work off the course of its original plan, and we’d either steer it back the plan or ask it update the plan to reflect what was actually happening.
-
The four entities working on this were Nate, me, Sonnet-3.5, and … the compiler. The fact that we were generating C code was part of what made this work relatively well, because the compiler could detect certain classes of errors right away. Now that I think about it, this probably would not have worked as well if we were generating python!
-
The notebook is so long that we blew past Sonnet’s context limit multiple times. Then we used
%aireset within the same notebook, and fresh prompts to reload old context and the story so far.
Here’s a screenshot of the kind of prompting we used to resume-mid notebook, to give a flavor of it:

Here’s prompting to catch up on work so far
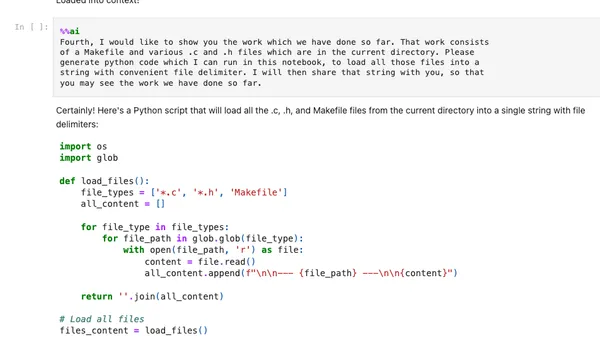
Notice how in this prompt we’re catching sonnet up with its own plan, which it marked as completed vs not:
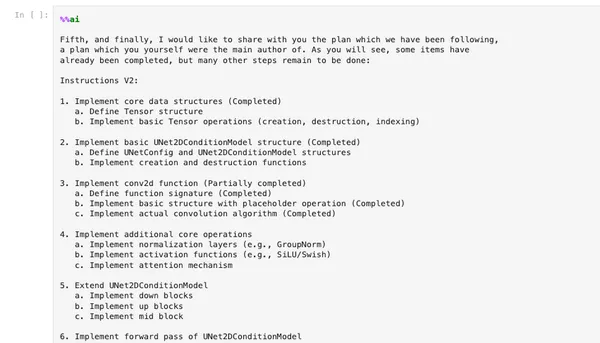
-
As we proceeded, we could refer to tasks using the outline heading numbers for clarity. And we used a slightly informal tone with Sonnet. Did this help? I imagine that being dangerous, menacing, or insulting would probably have distracted the model, so on that theory perhaps being friendly rather than completely businesslike helped? (I’d like to think so. 🙂 )
-
Nate and I were absolutely amazed how well this seemed to be working. Was it working that well? We were certainly not writing the C code ourselves and convincing ourselves that the model did it, a la Clever Hans. But maybe the model was “simply” recalling a C-based diffusion implementation that’s out there on the net? Maybe it would have hit the wall as soon as it reached the stage where it implemented a training loop, for instance? I’m not sure.
Possible Lessons
My main takeaways:
-
It is an unfamiliar way to work, uncomfortable but definitely worth exploring, to just prompt the model to generate technical material like code faster than you can check it, if you have some other system for checking it (a compiler), and if you have some other intuitive guide which you use to steer the process (like an outline and overall understanding). Nate said it felt like we were micromanaging an expert working for us.
-
It’s worth trying ingesting large amounts of diverse context indiscriminately. In particular it might be handy to ingest github repos relatively indiscriminately (starting with the readme, then maybe only getting sources, etc.)
-
It’s handy to have indiscriminate context ingester functions around (this is part of what has inspired work on the read module on the V2 branch of ContextKit.

Footnotes
-
AIMagic was finally published and open sourced in early 2026. ↩